A machine learning engineering team has written predictions computed in a batch job to a Delta table for querying. However, the team has noticed that the querying is running slowly. The team has alreadytuned the size of the data files. Upon investigating, the team has concluded that the rows meeting the query condition are sparsely located throughout each of the data files.
Based on the scenario, which of the following optimization techniques could speed up the query by colocating similar records while considering values in multiple columns?
A data scientist has written a function to track the runs of their random forest model. The data scientist is changing the number of trees in the forest across each run.
Which of the following MLflow operations is designed to log single values like the number of trees in a random forest?
A machine learning engineer is using the following code block as part of a batch deployment pipeline:

Which of the following changes needs to be made so this code block will work when theinferencetable is a stream source?
A machine learning engineer is migrating a machine learning pipeline to use Databricks Machine Learning. They have programmatically identified the best run from an MLflow Experiment and stored its URI in themodel_urivariable and its Run ID in therun_idvariable. They have also determined that the model was logged with the name"model". Now, the machine learning engineer wants to register that model in the MLflow Model Registry with the name"best_model".
Which of the following lines of code can they use to register the model to the MLflow Model Registry?
Which of the following operations in Feature Store Client fs can be used to return a Spark DataFrame of a data set associated with a Feature Store table?
Which of the following tools can assist in real-time deployments by packaging software with its own application, tools, and libraries?
A machine learning engineer has developed a model and registered it using the FeatureStoreClient fs. The model has model URI model_uri. The engineer now needs to perform batch inference on customer-level Spark DataFrame spark_df, but it is missing a few of the static features that were used when training the model. The customer_id column is the primary key of spark_df and the training set used when training and logging the model.
Which of the following code blocks can be used to compute predictions for spark_df when the missing feature values can be found in the Feature Store by searching for features by customer_id?
A data scientist has developed a scikit-learn modelsklearn_modeland they want to log the model using MLflow.
They write the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
A machine learning engineer is converting a Hyperopt-based hyperparameter tuning process from manual MLflow logging to MLflow Autologging. They are trying to determine how to manage nested Hyperopt runs with MLflow Autologging.
Which of the following approaches will create a single parent run for the process and a child run for each unique combination of hyperparameter values when using Hyperopt and MLflow Autologging?
A machine learning engineer wants to log feature importance data from a CSV file at path importance_path with an MLflow run for model model.
Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
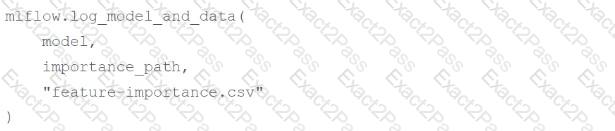

mlflow.log_data(importance_path, "feature-importance.csv")
mlflow.log_artifact(importance_path, "feature-importance.csv")
None of these code blocks tan accomplish the task.
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
A data scientist has developed a modelmodeland computed the RMSE of the model on the test set. They have assigned this value to the variablermse. They now want to manually store the RMSE value with the MLflow run.
They write the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
A data scientist set up a machine learning pipeline to automatically log a data visualization with each run. They now want to view the visualizations in Databricks.
Which of the following locations in Databricks will show these data visualizations?
Which of the following MLflow operations can be used to delete a model from the MLflow Model Registry?
After a data scientist noticed that a column was missing from a production feature set stored as a Delta table, the machine learning engineering team has been tasked with determining when the column was dropped from the feature set.
Which of the following SQL commands can be used to accomplish this task?