Last Update 4 hours ago Total Questions : 525
The Designing and Implementing a Data Science Solution on Azure content is now fully updated, with all current exam questions added 4 hours ago. Deciding to include DP-100 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our DP-100 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these DP-100 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any Designing and Implementing a Data Science Solution on Azure practice test comfortably within the allotted time.
You manage an Azure Machine Learning workspace.
You need to define an environment from a Docker image by using the Azure Machine Learning Python SDK v2.
Which parameter should you use?
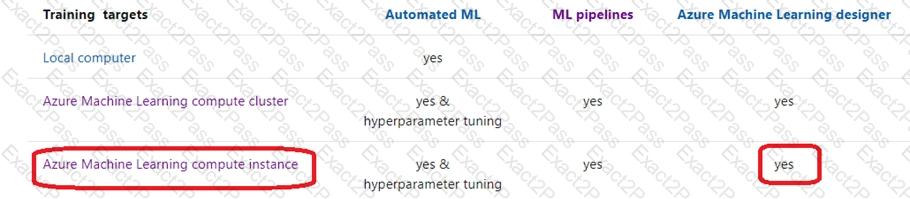
You create machine learning models by using Azure Machine Learning.
You plan to train and score models by using a variety of compute contexts. You also plan to create a new compute resource in Azure Machine Learning studio.
You need to select the appropriate compute types.
Which compute types should you select? To answer, drag the appropriate compute types to the correct requirements. Each compute type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

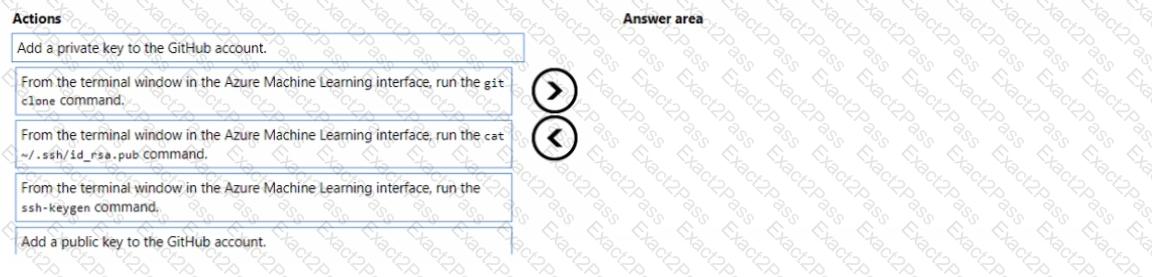
You have an existing GitHub repository containing Azure Machine Learning project files.
You need to clone the repository to your Azure Machine Learning shared workspace file system.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
You train classification and regression models by using automated machine learning.
You must evaluate automated machine learning experiment results. The results include how a classification model is making systematic errors in its predictions and the relationship between the target feature and the regression model ' s predictions. You must use charts generated by automated machine learning.
You need to choose a chart type for each model type.
Which chart types should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

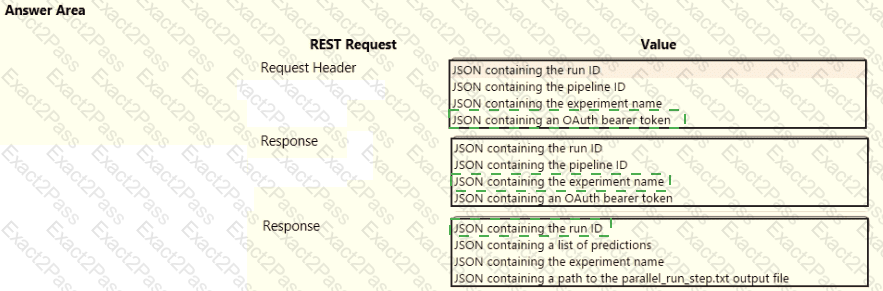
You create a batch inference pipeline by using the Azure ML SDK. You run the pipeline by using the following code:
from azureml.pipeline.core import Pipeline
from azureml.core.experiment import Experiment
pipeline = Pipeline(workspace=ws, steps=[parallelrun_step])
pipeline_run = Experiment(ws, ' batch_pipeline ' ).submit(pipeline)
You need to monitor the progress of the pipeline execution.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.

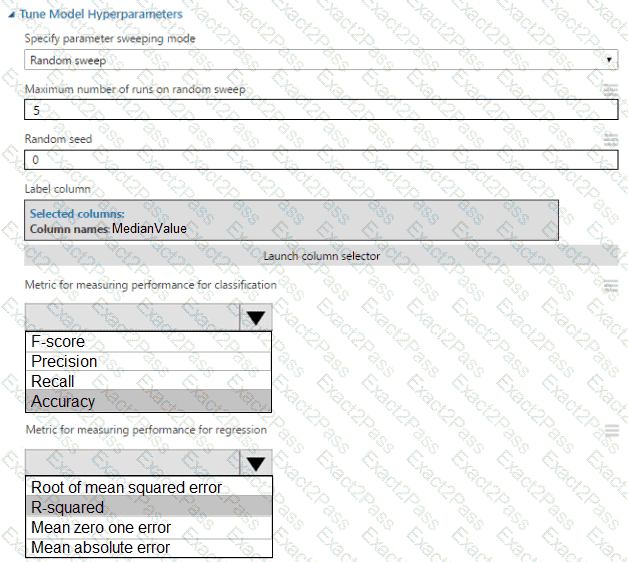
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
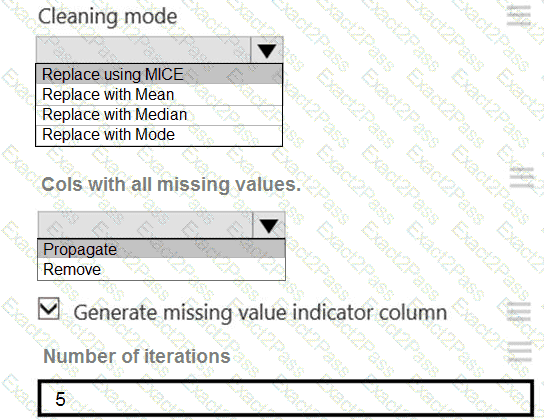
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You create a multi-class image classification deep learning model that uses a set of labeled images. You
create a script file named train.py that uses the PyTorch 1.3 framework to train the model.
You must run the script by using an estimator. The code must not require any additional Python libraries to be installed in the environment for the estimator. The time required for model training must be minimized.
You need to define the estimator that will be used to run the script.
Which estimator type should you use?
You are planning to register a trained model in an Azure Machine Learning workspace.
You must store additional metadata about the model in a key-value format. You must be able to add new metadata and modify or delete metadata after creation.
You need to register the model.
Which parameter should you use?
You manage an Azure Machine Learning workspace.
You plan to irain a natural language processing (NLP) tew classification model in multiple languages by using Azure Machine learning Python SDK v2. You need to configure the language of the text classification job by using automated machine learning. Which method of the TextClassifkationlob class should you use?