Last Update 5 hours ago Total Questions : 250
The UiPath Specialized AI Associate Exam (2023.10) content is now fully updated, with all current exam questions added 5 hours ago. Deciding to include UiPath-SAIAv1 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our UiPath-SAIAv1 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these UiPath-SAIAv1 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any UiPath Specialized AI Associate Exam (2023.10) practice test comfortably within the allotted time.
Which OCR (Optical Character Recognition) option is recommended to be initially utilized for document processing in a project?
What can be done in the Reports section of the dataset navigation bar in UiPath Communication Mining?
What are the main components of a digital business process?
When training labels and general fields in UiPath Communications Mining, what is the recommended approach to training efficiency?
In a Document Understanding project, the user needs to extract information from PDF documents with the following requirements:
The documents can contain scanned or digitally typed text.
The documents can contain checkboxes, and these must be extracted.
The automation must use the logical processors in the most efficient way to obtain the maximum degree of parallelism.What are the properties provided to the Digitize Document activity in the Digitize phase?
What additional information can be included in the exported data, apart from the extraction results?
Which of the following business processes is the most suitable for automation?
A developer needs to create a process for the Human Resources team. During the development, they try to run the workflow containing the following dictionary variable:
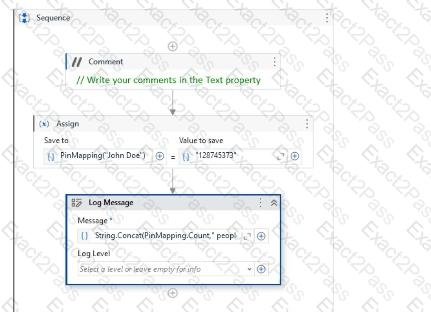
What is the possible cause of the error?
Where should a model be pinned in UiPath Communications Mining?
What is the page unit cost per extracted page for the RegEx Extractor?

