Last Update 22 hours ago Total Questions : 99
The SAS Statistical Business Analysis SAS9: Regression and Model content is now fully updated, with all current exam questions added 22 hours ago. Deciding to include A00-240 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our A00-240 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these A00-240 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any SAS Statistical Business Analysis SAS9: Regression and Model practice test comfortably within the allotted time.
The standard form of a linear regression model is:
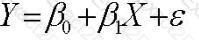
Which statement best summarizes the assumptions placed on the errors?
Which SAS program will detect collinearity in a multiple regression application?

Refer to the following exhibit:
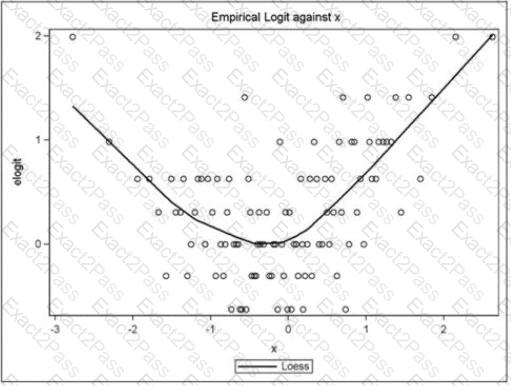
What is a correct interpretation of this graph?
Given the following LOGISTIC procedure:

What is the difference between the datasets OUTFILEJ and OUTFILE_2?
What is a benefit to performing data cleansing (imputation, transformations, etc.) on data after partitioning the data for honest assessment as opposed to performing the data cleansing prior to partitioning the data?
Refer to the REG procedure output:
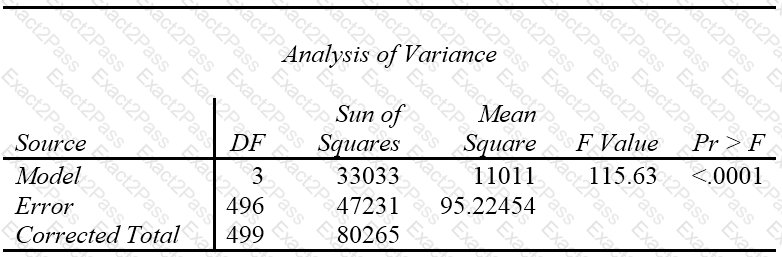
Calculate the coefficient of determination, R-Square.
Enter your numeric answer in the space below. Round to 4 decimal places (example: n.nnnn).
Refer to the lift chart:
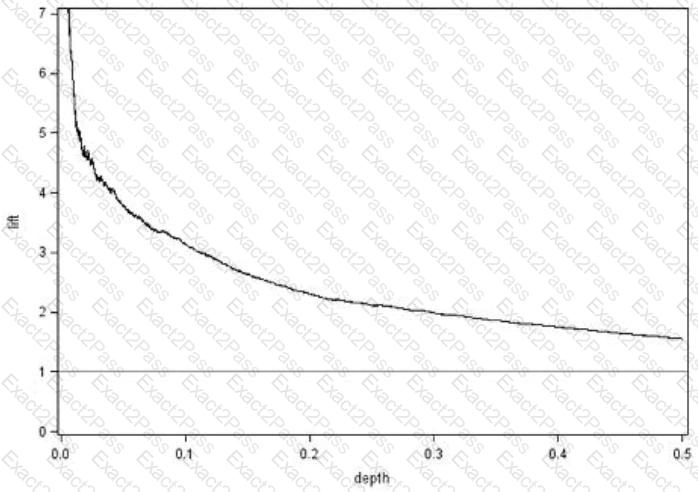
At a depth of 0.1, Lift = 3.14. What does this mean?
This question will ask you to provide a missing option.
A business analyst is investigating the differences in sales figures across 8 sales regions. The analyst is interested in viewing the regression equation parameter estimates for each of the design variables.
Which option completes the program to produce the regression equation parameter estimates?

Screening for non-linearity in binary logistic regression can be achieved by visualizing:
When working with smaller data sets (N < 200), which method is preferred to perform honest assessment?

