Last Update 5 hours ago Total Questions : 85
The CompTIA DataX Exam content is now fully updated, with all current exam questions added 5 hours ago. Deciding to include DY0-001 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our DY0-001 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these DY0-001 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any CompTIA DataX Exam practice test comfortably within the allotted time.
A data scientist is attempting to identify sentences that are conceptually similar to each other within a set of text files. Which of the following is the best way to prepare the data set to accomplish this task after data ingestion?
A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
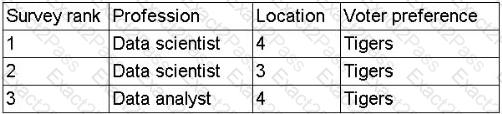
(Screenshot shows survey rankings for just two professions and a few locations, all voting for " Tigers " )
Which of the following is the most likely concern about the model ' s ability to predict the outcome of the vote?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?
A data scientist would like to model a complex phenomenon using a large data set composed of categorical, discrete, and continuous variables. After completing exploratory data analysis, the data scientist is reasonably certain that no linear relationship exists between the predictors and the target. Although the phenomenon is complex, the data scientist still wants to maintain the highest possible degree of interpretability in the final model. Which of the following algorithms best meets this objective?
A data scientist is building a model to predict customer credit scores based on information collected from reporting agencies. The model needs to automatically adjust its parameters to adapt to recent changes in the information collected. Which of the following is the best model to use?

