The enterprise analytics and distributed systems engineering landscape in 2026 demands highly integrated multi-engine architectures and automated lifecycle management controls. As modern organizations move away from fragmented cloud computing databases toward unified, SaaS-driven data lakehouses, data engineers must pivot away from manual system maintenance patterns toward software-defined operational configurations. Achieving the Microsoft Certified: Fabric Data Engineer Associate designation validates your master-tier capacity to design scalable loading patterns, enforce secure governance profiles, and build real-time streaming architectures natively within OneLake. However, many Azure data engineers, database administrators, and business intelligence leads struggle on this intensive, 100-minute professional validation because they rely on short-sighted preparation methods. Trusting flat, context-stripped answer registries or linear question tables found on unverified public forums cannot prepare you for the complex situational logic of configuring deployment pipeline rules or resolving cross-workspace item dependencies under live transactional processing workloads.
True success on this 40-to-60 question cloud analytics milestone requires a comprehensive, multi-dimensional grasp of full batch and streaming telemetry lifecycles, spanning from initial remote data ingestion to advanced telemetry-driven query performance tuning. Practitioners must demonstrate an expert command over delta lake storage formatting boundaries, notebook parameters, and the specialized query engines that drive Microsoft Fabric workloads. Candidates frequently spend several months searching for high-yield dp-700 exam questions online, hoping to locate an updated implementing data engineering solutions using microsoft fabric dp-700 study guide to measure their system engineering fluency, or searching for configuration matrices to verify their access permissions. Without interactive learning tracks, structured platform simulations, or targeted practical training that can provide actual help in exam preparation, passive reading fails to develop the critical diagnostic capabilities needed to handle data ingestion errors or isolate notebook processing bottlenecks within the active workspace environment.
At Exact2Pass, we replace passive reading with active, scenario-driven structural engineering exercises designed to build true platform confidence. Our premium preparation workspace simulates the functional operational layers, terminal prompt controls, and deployment rules of the active Fabric SaaS platform. We guide you through executing gap analyses on incoming data layers, authoring advanced PySpark transformations, building robust dimensional models, and monitoring resource allocation metrics using the Capacity Metrics App. This targeted training builds the exact capacity planning strategy and system deployment skills demanded by elite enterprise consultation teams, ensuring you pass your official proctored assessment on your very first try.
The DP-700 certification exam is engineered to evaluate your end-to-end data platform implementation and administration capabilities across modern corporate parameters, balancing core architecture technology comparisons with high-cognitive scenario questions. Our realistic simulation platform replicates active cloud operational consoles, autonomous pipeline orchestration engines, and real-time database query validation tools instead of serving up generic multi-choice questionnaires. You will master the underlying database separations, operator-driven data ingestion fields, and security-level dependencies of the active Microsoft ecosystem, preparing you to tackle any scenario-based infrastructure question with ease.
HOTSPOT
You have a Fabric workspace named Workspace1_DEV that contains the following items:
10 reports
Four notebooks
Three lakehouses
Two data pipelines
Two Dataflow Gen1 dataflows
Three Dataflow Gen2 dataflows
Five semantic models that each has a scheduled refresh policy
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST.
You deploy all the items from Workspace1_DEV to Workspace1_TEST.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You have a Fabric workspace named Workspace1 that contains a warehouse named DW1 and a data pipeline named Pipeline1.
You plan to add a user named User3 to Workspace1.
You need to ensure that User3 can perform the following actions:
View all the items in Workspace1.
Update the tables in DW1.
The solution must follow the principle of least privilege.
You already assigned the appropriate object-level permissions to DW1.
Which workspace role should you assign to User3?
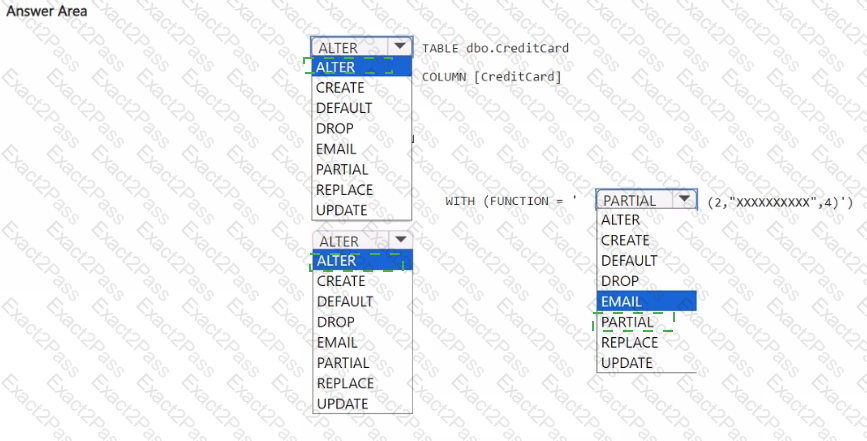
You have a Fabric workspace named Workspace1 that contains a warehouse named Warehouse2. A team of data analysts has Viewer role access to Workspace1. You create a table by running the following statement.
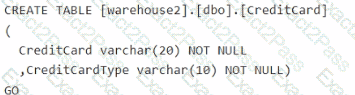
You need to ensure that the team can view only the first two characters and the last four characters of the Creditcard attribute.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
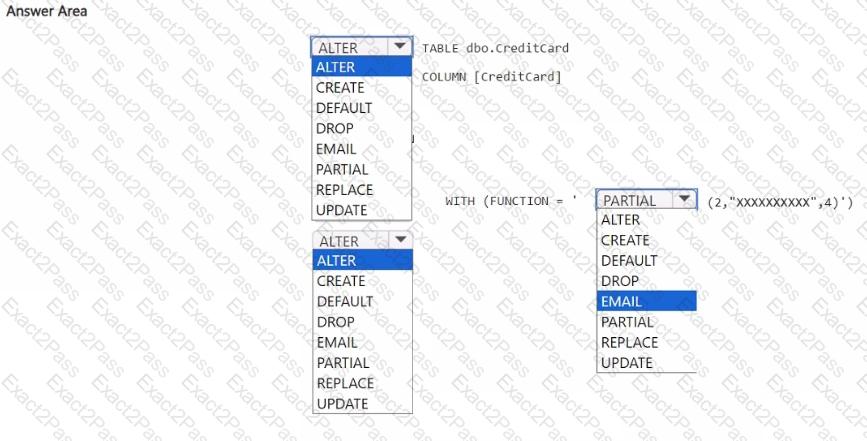
HOTSPOT
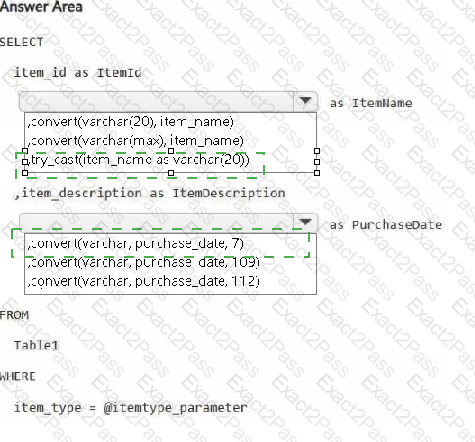
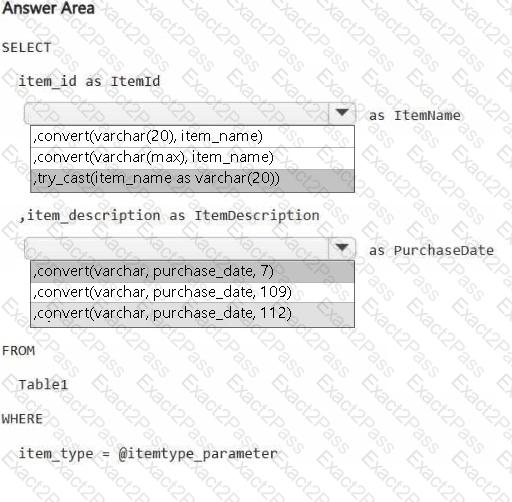
You have a Fabric workspace.
You are debugging a statement and discover the following issues:
Sometimes, the statement fails to return all the expected rows.
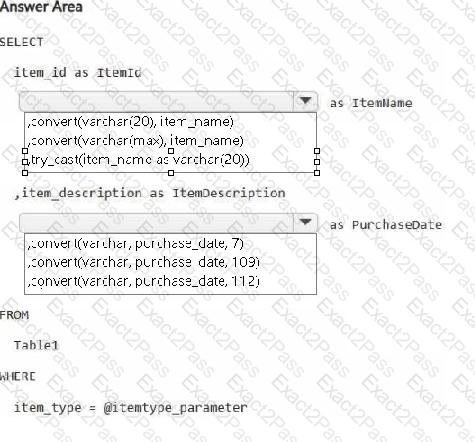
The PurchaseDate output column is NOT in the expected format of mmm dd, yy.
You need to resolve the issues. The solution must ensure that the data types of the results are retained. The results can contain blank cells.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal?
You have a Fabric workspace that contains a write intensive warehouse named DW1. DW1 stores staging tables that are used to load a dimensional model. The tables are often read once, dropped, and then recreated to process new data.
You need to minimize load time of data from sources to staging tables in DW1.
What should you do?
You have a Fabric workspace named Workspace1 that contains an Apache Spark job definition named Job1.
You have an Azure SQL database named Source1 that has public internet access disabled.
You need to ensure that Job1 can access the data in Source1.
What should you create?
HOTSPOT
You are processing streaming data from an external data provider.
You have the following code segment.

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

You have a Fabric workspace named Workspace1 that contains a lakehouse named Lakehouse1. Lakehouse1 contains the following tables:
Orders
Customer
Employee
The Employee table contains Personally Identifiable Information (PII).
A data engineer is building a workflow that requires writing data to the Customer table, however, the user does NOT have the elevated permissions required to view the contents of the Employee table.
You need to ensure that the data engineer can write data to the Customer table without reading data from the Employee table.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.
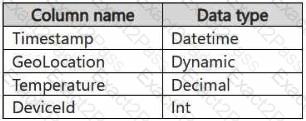
Reference contains reference data in the following format.
Both tables contain millions of rows.
You have the following KQL queryset.

You need to reduce how long it takes to run the KQL queryset.
Solution: You change project to extend.
Does this meet the goal?



 C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg
C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg

