Last Update 8 hours ago Total Questions : 60
The NetApp Certified Support Engineer ONTAP Specialist content is now fully updated, with all current exam questions added 8 hours ago. Deciding to include NS0-593 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our NS0-593 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these NS0-593 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any NetApp Certified Support Engineer ONTAP Specialist practice test comfortably within the allotted time.
An administrator receives the following error message:
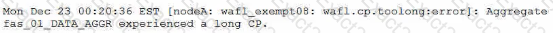
What are two causes for this error? (Choose two.)
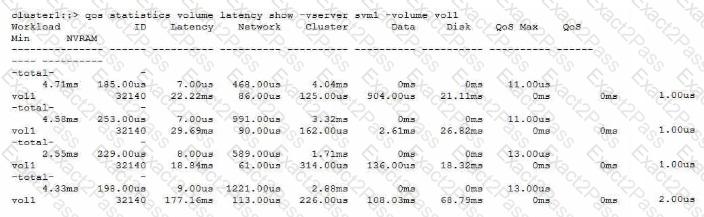
Referring to the exhibit, from which delay center is most of the latency for voll?
When you review performance data for a NetApp ONTAP cluster node, there are back-to-back (B2B) type consistency points (CPs) found occurring on the loot aggregate.
In this scenario, how will performance of the client operations on the data aggregates be affected?
You have a customer who is concerned with high CPU and disk utilization on their SnapMirror destination system. They are worried about high CPU and disk usage without any user operations.
In this situation, what should you tell the customer?
A customer reports that some of their client computers are unable to access a FlexGroup over CIFS. This problem involves only their older Windows XP clients and some printers and scanners.
In this scenario, which statement Is correct?
A customer enabled NFSv4.0 on an SVM and changed the client mount from NFSv3 to NFSv4. Afterwards, the customer found that the directory owner was changed from root to nobody.
In this scenario, which statement is true?
Recently, a CIFS SVM was deployed and is working. The customer wants to use the Dynamic DNS (DDNS) capability available in NetApp ONTAP to easily advertise both data UFs to their clients. Currently. DNS is only responding with one data LIF. DDNS is enabled on the domain controllers.
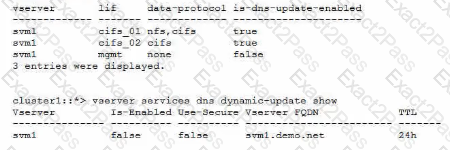
Referring to the exhibit, which two actions should be performed to enable DDNS updates to work? (Choose two.)
Your customer wants to access a LUN on a FAS 8300 system from a VMware ESXi server through the FC protocol. They already created a new SVM, volume. LUN, and igroup for this purpose. The customer reports that the server's FC HBA port Is online, but the LUN does not show up.
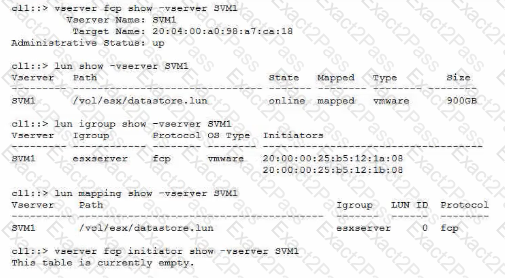
Referring to the exhibit, what is the reason for this problem?
You Just used the CLI to create a NetApp ONTAP FlexGroup Volume on a NetApp Cloud Volumes ONTAP instance. After creation, you notice odd behavior in NetApp Cloud Manager.
In this scenario, what Is the reason for this behavior?
A user reports that a colleague saved a file called Test.txt from a UNIX system to a multiprotocol volume. When opening the file later from a Windows system, it was not the file that they wanted. The file that they wanted was named TEST~1.TXT.
Which statement explains this behavior?

