Last Update 5 hours ago Total Questions : 211
The UiPath Certified Professional Specialized AI Professional v1.0 content is now fully updated, with all current exam questions added 5 hours ago. Deciding to include UiPath-SAIv1 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our UiPath-SAIv1 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these UiPath-SAIv1 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any UiPath Certified Professional Specialized AI Professional v1.0 practice test comfortably within the allotted time.
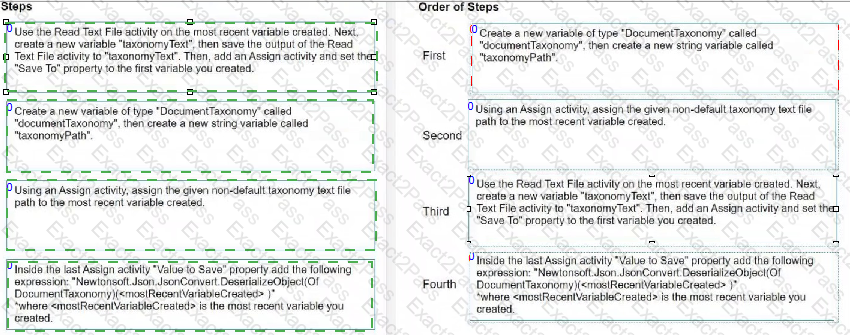
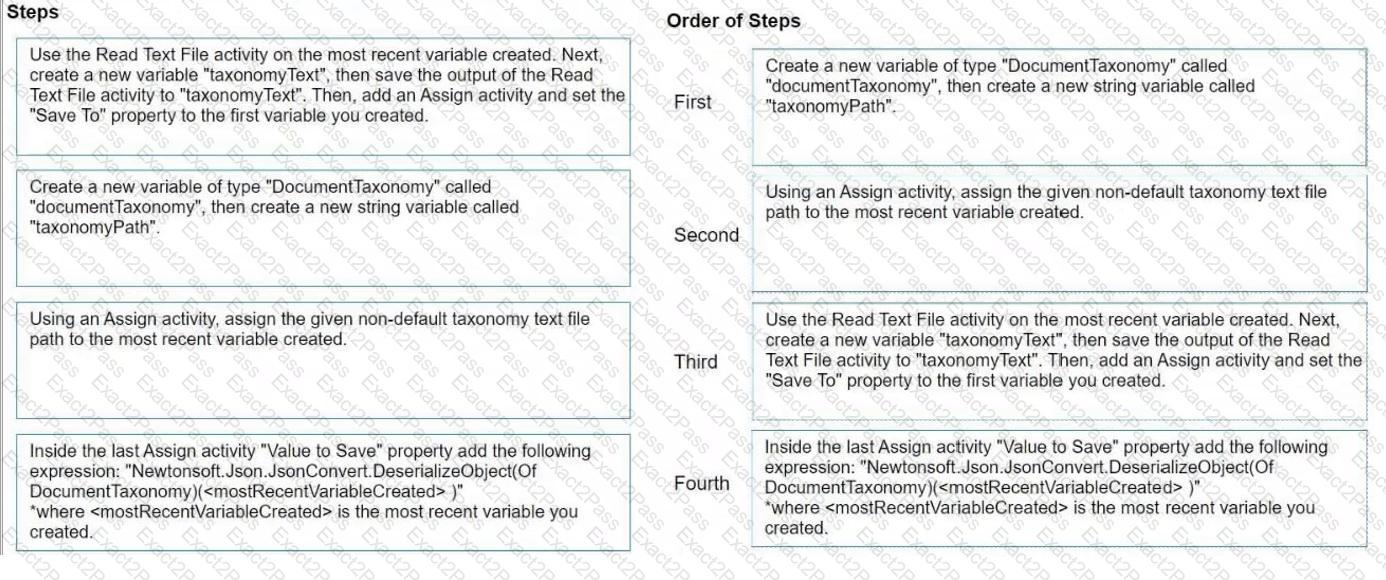
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the " Left " and drop them on the " Right " in the correct order.
How does UiPath Document Understanding handle structured documents with fixed formats?
When dealing with variable-length data, or data spanning over multiple pages of the document (e.g. item tables), what is the recommended data extraction methodology to be used?
Which of the following is a characteristic of a poorly-performing model in UiPath Communications Mining?
What is the role of the dispatcher in the Document Understanding Process?
What is the purpose of the " Explore " phase in UiPath Communications Mining?
Given the following scenario:
• You have a trained version of the Document Understanding Model with 1000 pages called v22.10.0.1.
• You have an evaluation dataset of 100 pages that gave a score of 0.72 for v22.10.0.1.
• The business team labeled 800 pages and they ask for an increment of the Model that would contain all 1000+800 pages.
What is the first recommended pipeline run configuration to create the new version?
Which is the correct description of the Configure Extractors Wizard?
How do you choose the appropriate document processing methodology?
Which are all the options for managing ML Skills?