Last Update 4 hours ago Total Questions : 85
The CompTIA DataX Exam content is now fully updated, with all current exam questions added 4 hours ago. Deciding to include DY0-001 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our DY0-001 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these DY0-001 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any CompTIA DataX Exam practice test comfortably within the allotted time.
A data scientist is merging two tables. Table 1 contains employee IDs and roles. Table 2 contains employee IDs and team assignments. Which of the following is the best technique to combine these data sets?
A data scientist has built an image recognition model that distinguishes cars from trucks. The data scientist now wants to measure the rate at which the model correctly identifies a car as a car versus when it misidentifies a truck as a car. Which of the following would best convey this information?
A data scientist receives an update on a business case about a machine that has thousands of error codes. The data scientist creates the following summary statistics profile while reviewing the logs for each machine:
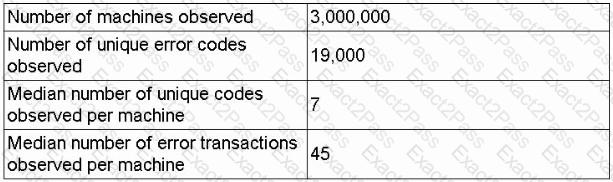
| Number of machines observed | 3,000,000
| Number of unique error codes observed | 19,000
| Median number of unique codes per machine | 7
| Median number of error transactions | 45
Which of the following is the most likely concern with respect to data design for model ingestion?
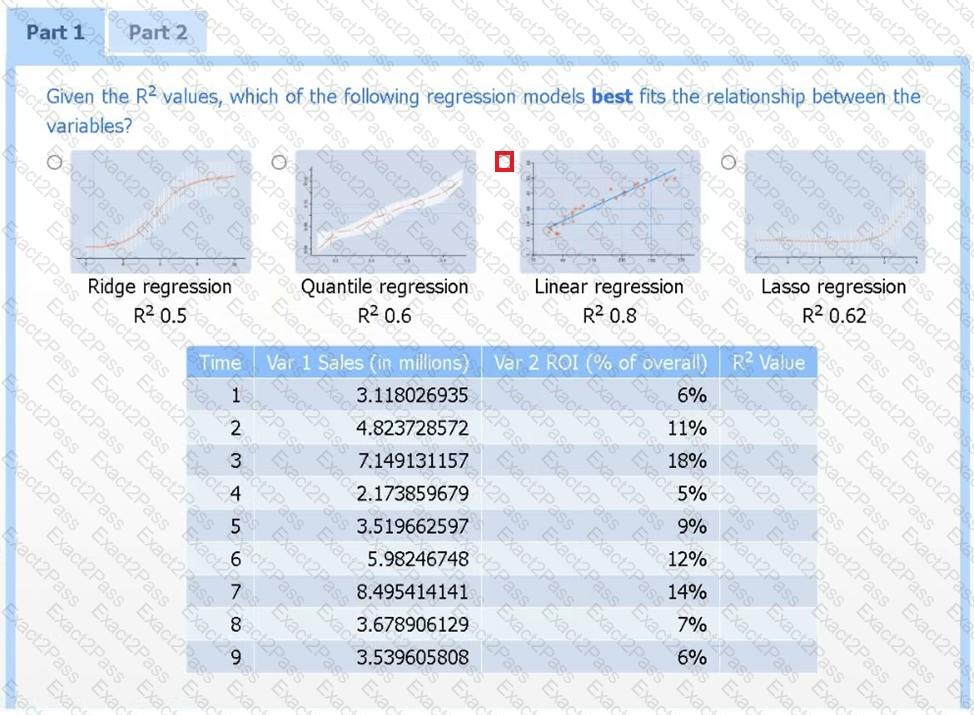
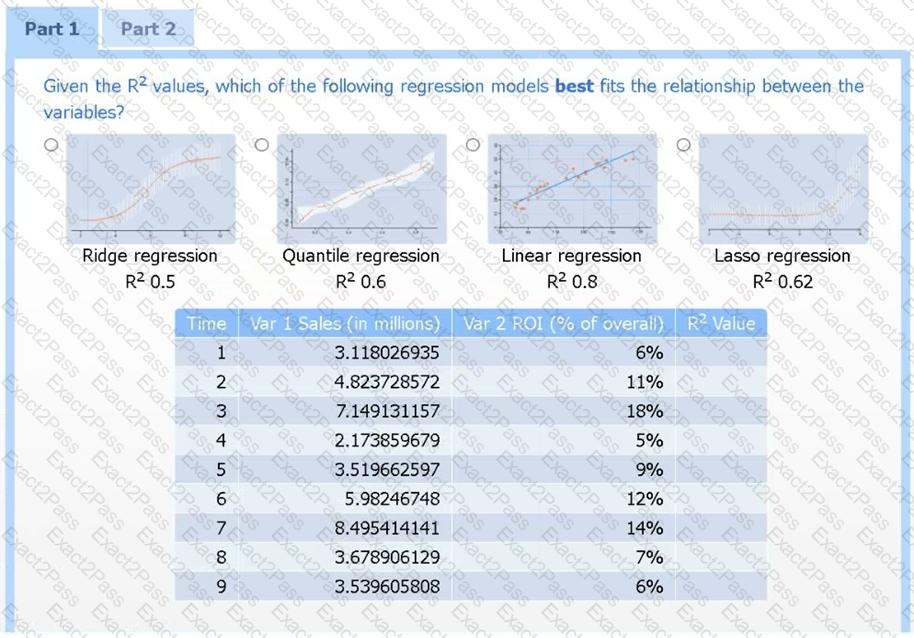
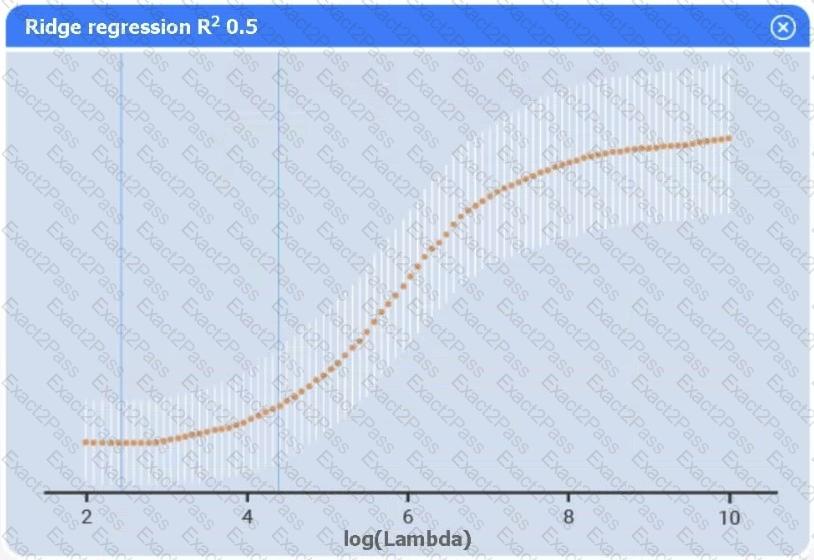
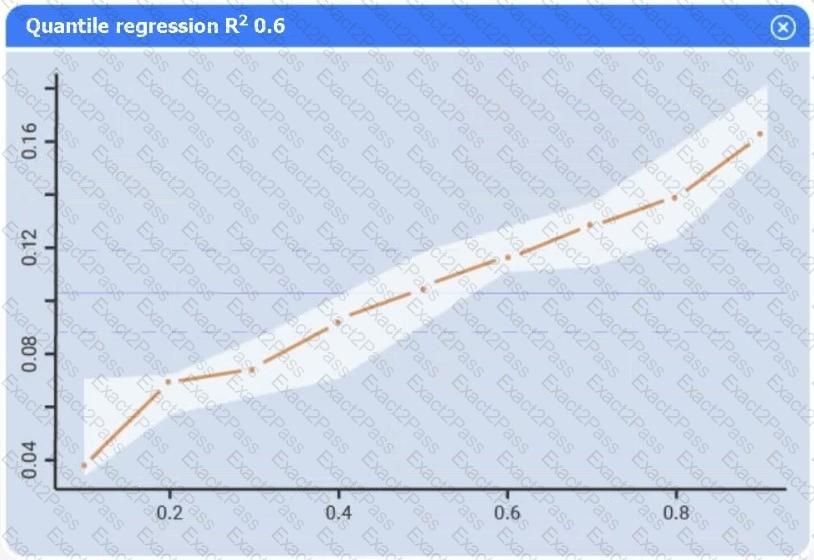
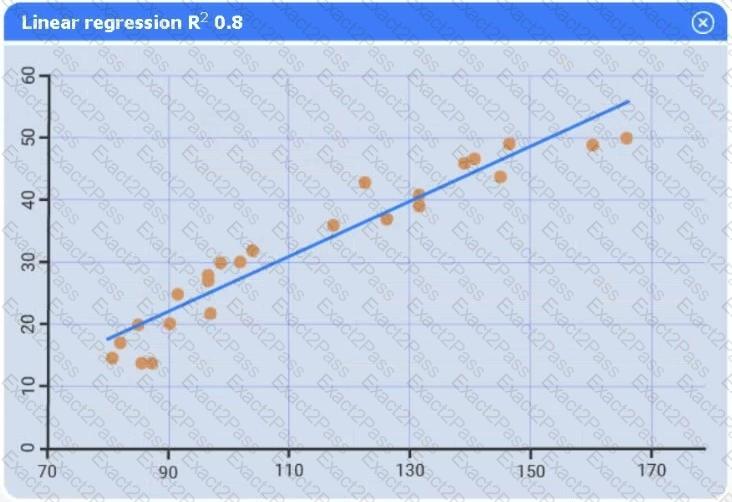
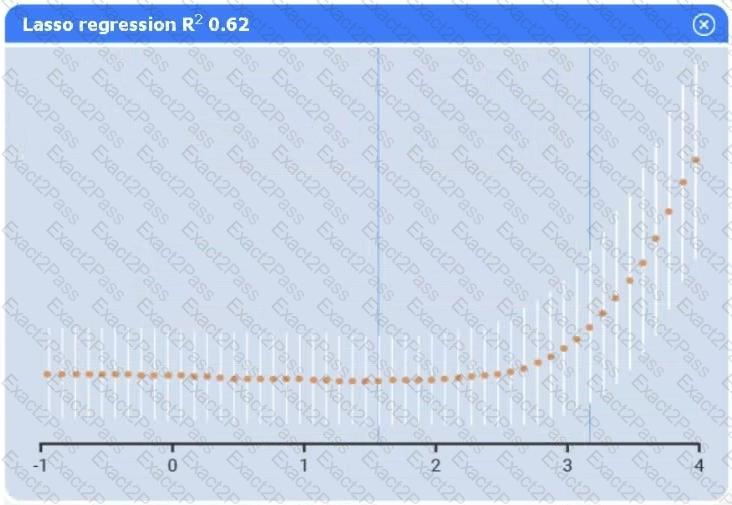
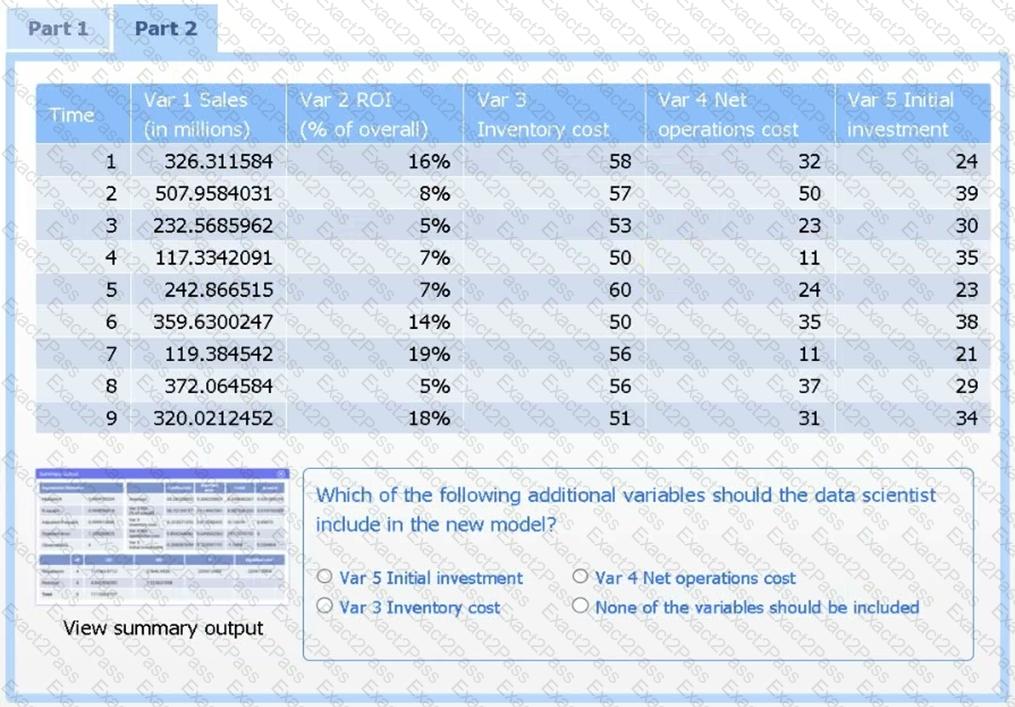
A data scientist needs to determine whether product sales are impacted by other contributing factors. The client has provided the data scientist with sales and other variables in the data set.
The data scientist decides to test potential models that include other information.
INSTRUCTIONS
Part 1
Use the information provided in the table to select the appropriate regression model.
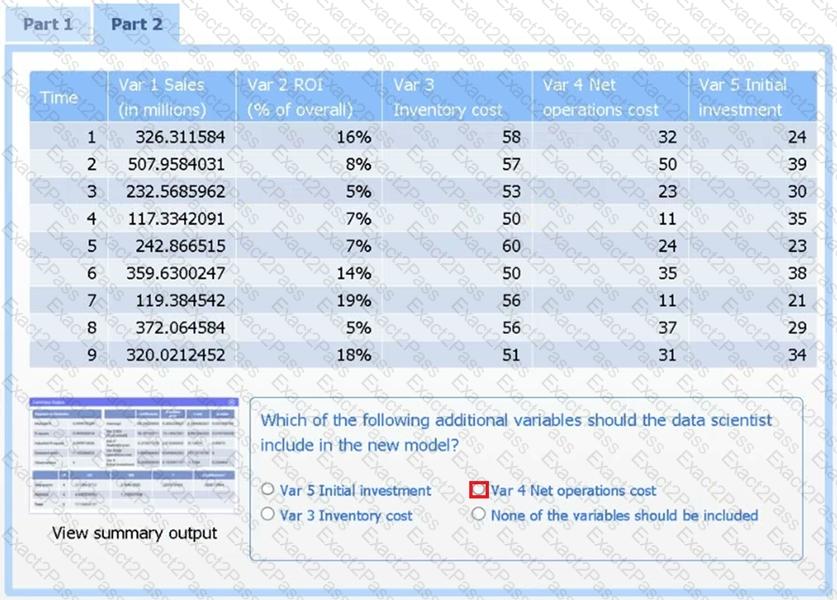
Part 2
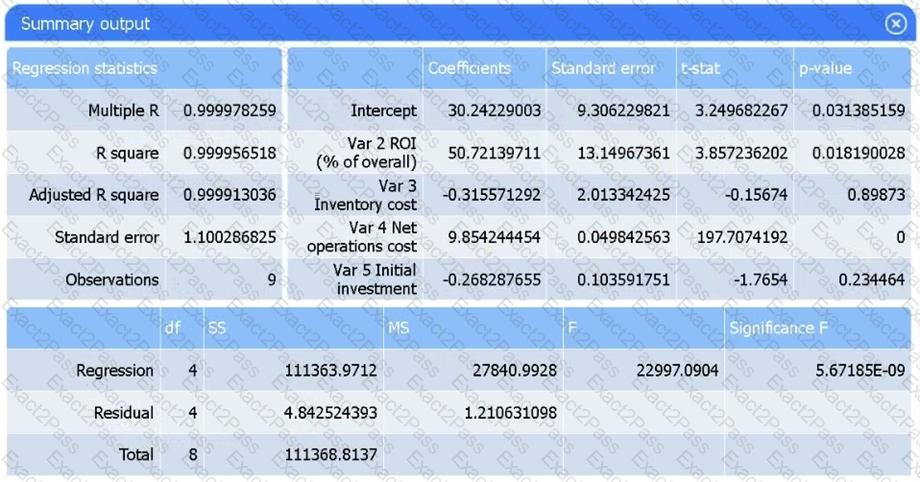
Review the summary output and variable table to determine which variable is statistically significant.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.
A data scientist observes findings that indicate that as electrical grids in a country become more and more connected over time, the frequency of brownouts and blackouts in total decrease, and the frequency of major brownouts and blackouts increase. Which of the following distribution metrics could best be identified?
A data scientist is preparing to brief a non-technical audience that is focused on analysis and results. During the modeling process, the data scientist produced the following artifacts:
Which of the following artifacts should the data scientist include in the briefing? (Choose two.)
Which of the following does k represent in the k-means model?
A movie production company would like to find the actors appearing in its top movies using data from the tables below. The resulting data must show all movies in Table 1, enriched with actors listed in Table 2.
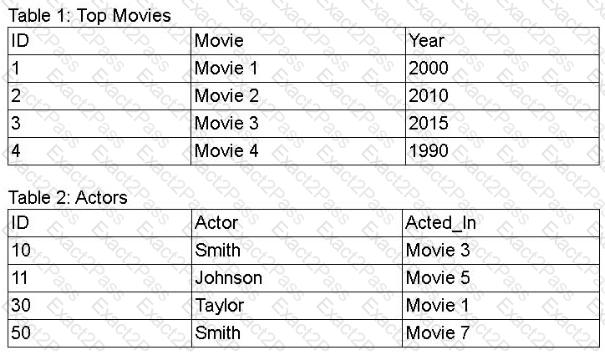
Which of the following query operations achieves the desired data set?
A statistician notices gaps in data associated with age-related illnesses and wants to further aggregate these observations. Which of the following is the best technique to achieve this goal?
A data scientist is building a forecasting model for the price of copper. The only input in this model is the daily price of copper for the last ten years. Which of the following forecasting techniques is the most appropriate for the data scientist to use?