Last Update 21 hours ago Total Questions : 58
The Implementing Data Engineering Solutions Using Azure Databricks content is now fully updated, with all current exam questions added 21 hours ago. Deciding to include DP-750 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our DP-750 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these DP-750 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any Implementing Data Engineering Solutions Using Azure Databricks practice test comfortably within the allotted time.
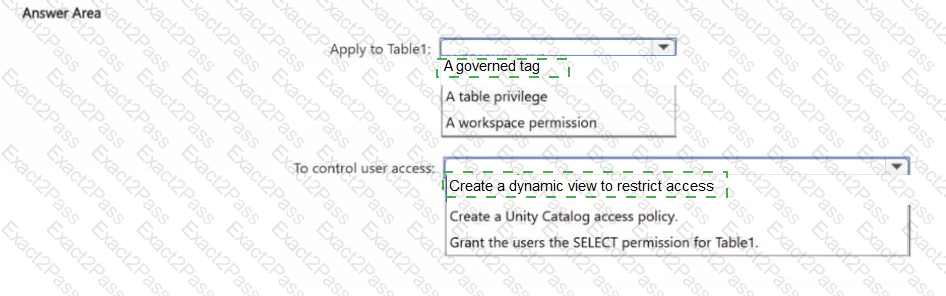
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named CatalogV Catalog1 contains a schema named Schema! and a table named Table1.
You need to ensure that access to the data in Table1 is controlled by using attribute based access control (ABAC).
What should you apply to Table1, and how should you control access for users? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You have a Lakeflow Spark Declarative Pipelines {SDP) pipeline in Azure Databricks. The pipeline ingests transaction data into a table named Table1.
You need to ensure that in the event of an invalid record, the pipeline continues to run. The solution must meet the following requirements:
• Invalid records must NOT be written to Table 1.
• Invalid records must be preserved for review.
• Minimize development effort
What should you do?
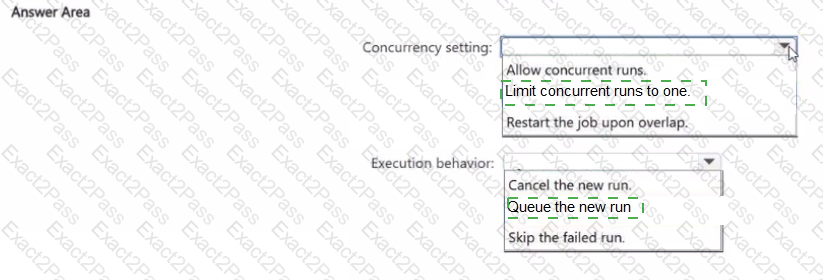
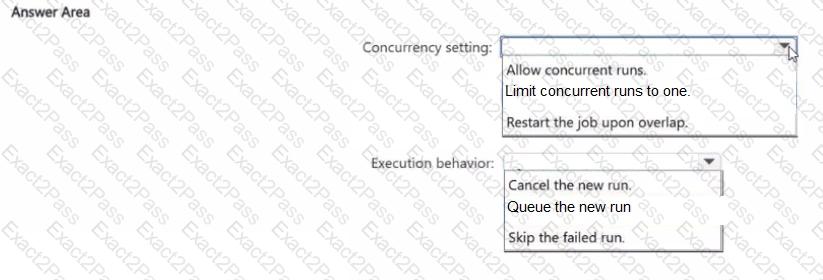
You have an Azure Databricks workspace that contains a job in Lakeflow Jobs named Job1.
Job! runs every hour.
Occasionally, the job run takes longer than one hour to complete. Overlapping runs must be prevented to avoid data corruption.
You need to configure the job scheduling behavior.
What should you configure? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
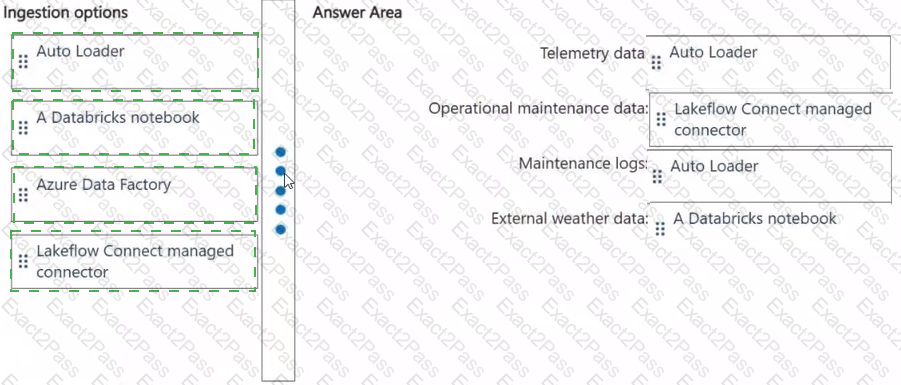
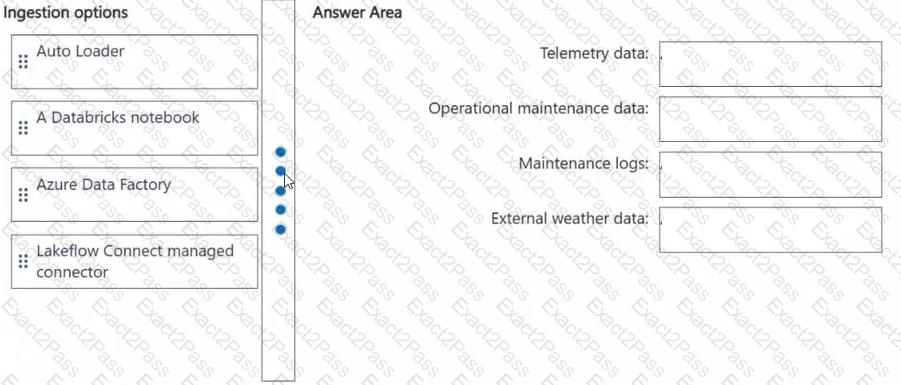
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
You have an Azure Databricks workspace that is enabled for Unity Catalog
You have an Apache Spark Structured Streaming job that writes data to a Delta table.
After the cluster restarts, the streaming job reprocesses previously ingested data
You need to prevent the streaming job from reprocessing the data after the cluster restarts.
What should you do?
You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
• The schemas and tables can be queried in Databricks.
• The schemas and tables appear alongside other Unity Catalog objects.
• The data is NOT copied into Databricks-managed storage.
Solution: You create a Databricks access connector.
Does this meet the goal?