Last Update 4 hours ago Total Questions : 525
The Designing and Implementing a Data Science Solution on Azure content is now fully updated, with all current exam questions added 4 hours ago. Deciding to include DP-100 practice exam questions in your study plan goes far beyond basic test preparation.
You'll find that our DP-100 exam questions frequently feature detailed scenarios and practical problem-solving exercises that directly mirror industry challenges. Engaging with these DP-100 sample sets allows you to effectively manage your time and pace yourself, giving you the ability to finish any Designing and Implementing a Data Science Solution on Azure practice test comfortably within the allotted time.
You are managing an Azure Machine Learning workspace.
You must tune a hyperparameter for a neural network model. The learning rate must be a continuous hyperparameter between 0.001 and 0.1. The batch size can be 32.64. or 128.
You need to select the appropriate search space for each parameter.
Which search space should you use? To answer, move the appropriate search spaces to the correct hyperparameters. You may use each search space option once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

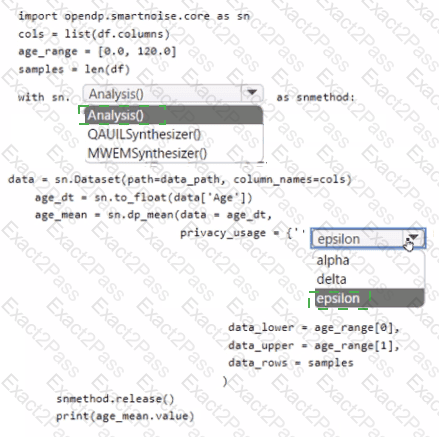
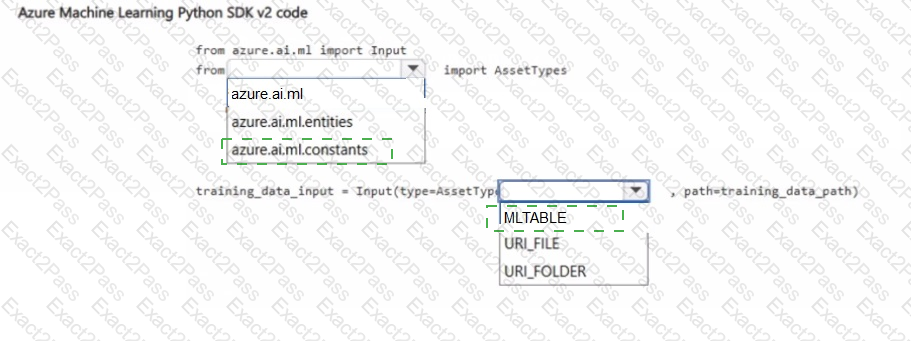
You create an Azure Machine Learning workspace. You use the Azure Machine Learning Python SDK v2 to create a compute cluster.
The compute cluster must run a training script. Costs associated with running the training script must be minimized.
You need to complete the Python script to create the compute cluster.
How should you complete the script? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
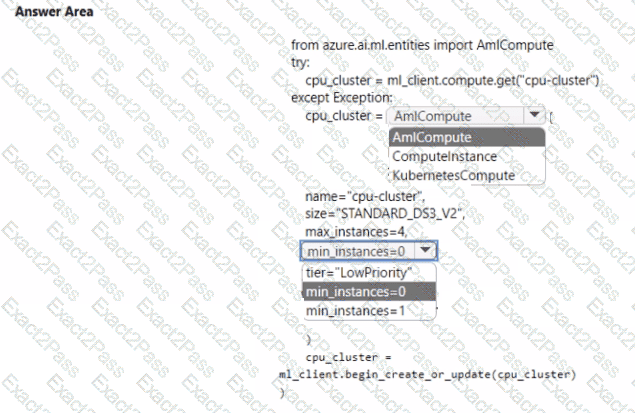
You have a model with a large difference between the training and validation error values.
You must create a new model and perform cross-validation.
You need to identify a parameter set for the new model using Azure Machine Learning Studio.
Which module you should use for each step? To answer, drag the appropriate modules to the correct steps. Each module may be used once or more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You manage an Azure Machine Learning workspace named workspace 1 with a compute instance named computet.
You must remove a kernel named kernel 1 from computet1. You connect to compute 1 by using noa terminal window from workspace 1.
You need to enter a command in the terminal window to remove kernel 1.
Which command should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection it worth one point.

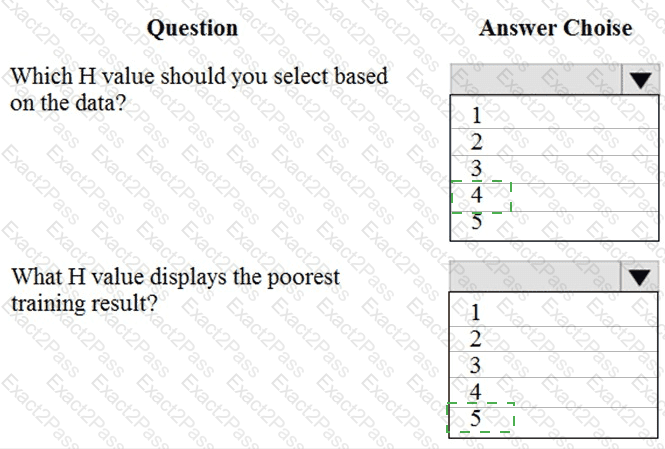
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

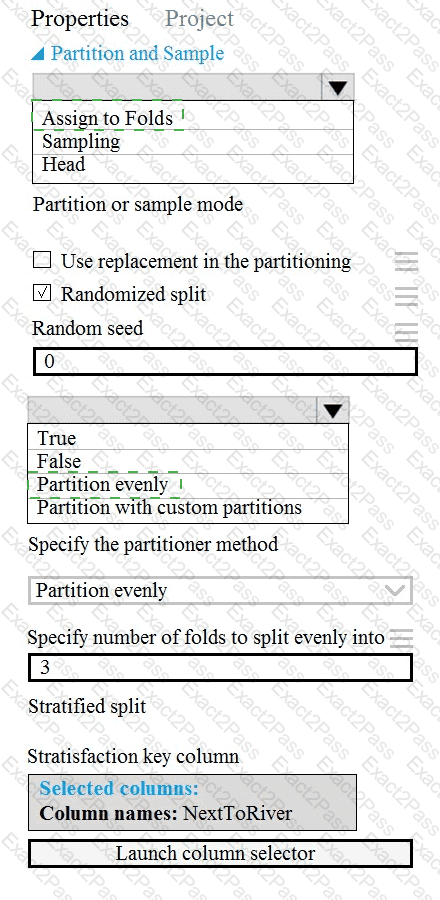
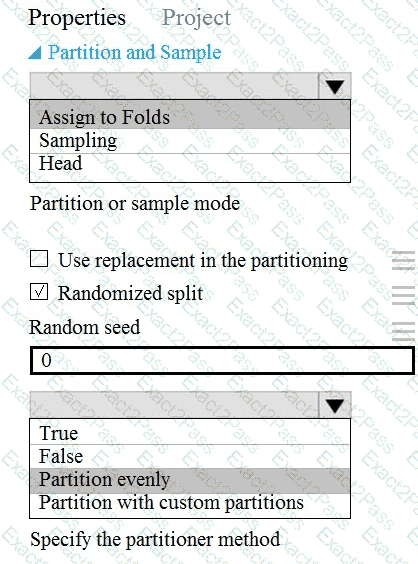
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

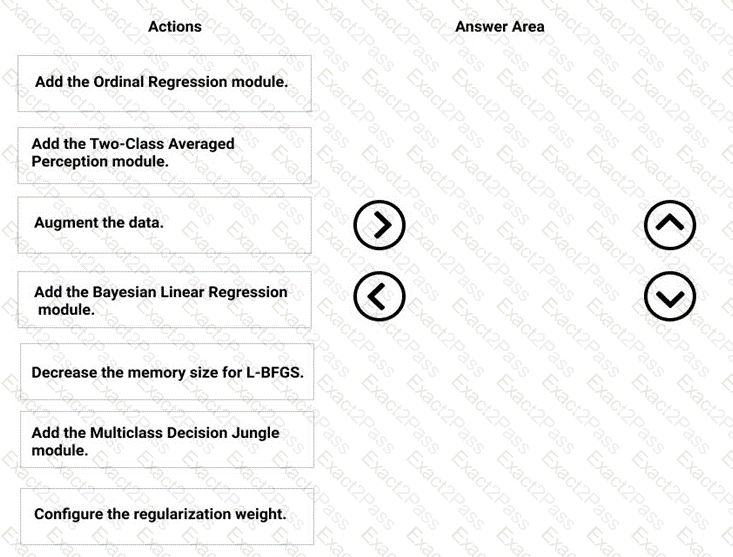
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
You plan to build a team data science environment. Data for training models in machine learning pipelines will
be over 20 GB in size.
You have the following requirements:
Models must be built using Caffe2 or Chainer frameworks.
Data scientists must be able to use a data science environment to build the machine learning pipelines and train models on their personal devices in both connected and disconnected network environments.
Personal devices must support updating machine learning pipelines when connected to a network.
You need to select a data science environment.
Which environment should you use?
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a
website. You have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
You are using the Azure Machine Learning Service to automate hyperparameter exploration of your neural network classification model.
You must define the hyperparameter space to automatically tune hyperparameters using random sampling according to following requirements:
The learning rate must be selected from a normal distribution with a mean value of 10 and a standard deviation of 3.
Batch size must be 16, 32 and 64.
Keep probability must be a value selected from a uniform distribution between the range of 0.05 and 0.1.
You need to use the param_sampling method of the Python API for the Azure Machine Learning Service.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.